- What is Aggregate Data
- Aggregation Annotations
- OData Interpretation of Aggregation Annotations
- Requesting Data from an Aggregated Entity
本功能要求 SAP NetWeaver AS for ABAP 7.52, SP02 及以上版本.
What is Aggregate Data
什么是合计数据, 就是把单个数值按一定的含义进行合并. 常见的聚合函数有:
- sum
- minimum
- maximum
- average
还有
- count
- distinct count
所有这些函数 SADL 框架都支持.
为了使前端能通过 OData 获取聚合数据, 需要在 CDS 中用 Annotations 对聚合相关字段进行注解. 最终 CDS 在生成 OData 时会被 SADL 框架截获并生成聚合功能.
List Reporting App of Sales Order Items with Aggregate Data
// TODO Aggregate Data in List Reporting
Aggregation Annotations
注解 @Aggregation.Default: #<AGGR_FUNCTION> 是用来注明某个字段是可以被聚合的.
只有度量(measures)字段才能被合计注解, 度量字段是指可以被聚合的数值类型的字段, 日期字段也可以被聚合函数如 maximum, minimum, count, distinct count 计算. 度量字段一般有单位: 大小, 金额, 度等.
CDS 中除了度量之外的字段称为维度(dimensions)字段, 维度提供了结构化的标签信息, 他们与对数据分组和排序有关.
CDS Aggregation Annotations 有
@Aggregation.Default: #SUM@Aggregation.Default: #MAX@Aggregation.Default: #MIN@Aggregation.Default: #AVG@Aggregation.Default: #COUNT@Aggregation.Default: #COUNT_DISTINCT
the Presentation in the UI
对于聚合字段 OData 是通过选择不同的维度字段(dimensions)进行分组聚合的, 当我们在调用 OData Service 时指定了某些维度字段, SADL 会根据这些信息生成相应的 SQL 语句对数据进行聚合, 如果不指定维度字段只有度量字段则也会进行聚合. 但对于前端来说, 有时我们不指定维度字段但也不想对度量字段聚合, 那么我们就需要使用 @UI.presentationVariant: [{requestAtLeast: ['<TECHNICAL_KEY>']}] 注解说明至少需要的维度技术字段.
@UI.presentationVariant: [{requestAtLeast: ['SalesOrderID','ItemPosition']}]
define view ZDEMO_C_SOI_ANLY
as select from SEPM_I_SalesOrderItem_E as Item
association [0..1] to SEPM_I_Product_E as _Product on $projection.Product = _Product.Product
association [0..1] to ZDEMO_C_SO_ANLY as _SalesOrder on $projection.SalesOrderID = _SalesOrder.SalesOrder
{
key SalesOrder as SalesOrderID,
key SalesOrderItem as ItemPosition,
Item._SalesOrder.Customer as CustomerID,
@Consumption.groupWithElement: 'CustomerID'
Item._SalesOrder._Customer.CompanyName as CompanyName,
@ObjectModel.foreignKey.association: '_Product'
Product as Product,
@Consumption.groupWithElement: 'Product'
_Product.ProductCategory as ProductCategory,
@Semantics.currencyCode: true
TransactionCurrency as CurrencyCode,
@Semantics.currencyCode: true
cast( 'EUR' as abap.cuky ) as TargetCurrency,
@Aggregation.Default: #SUM
@Semantics.amount.currencyCode: 'TargetCurrency'
CURRENCY_CONVERSION(
amount => Item.GrossAmountInTransacCurrency,
source_currency => Item.TransactionCurrency,
target_currency => cast( 'EUR' as abap.cuky ),
exchange_rate_date => cast( '20180315' as abap.dats ),
error_handling => 'SET_TO_NULL' ) as ConvertedGrossAmount,
@Semantics.amount.currencyCode: 'CurrencyCode'
@Aggregation.Default: #AVG
GrossAmountInTransacCurrency as GrossAmount,
@Semantics.amount.currencyCode: 'CurrencyCode'
@Aggregation.Default: #MIN
NetAmountInTransactionCurrency as NetAmount,
@Semantics.amount.currencyCode: 'CurrencyCode'
@Aggregation.Default: #MAX
TaxAmountInTransactionCurrency as TaxAmount,
@Aggregation.Default: #COUNT
cast ( 1 as abap.int4 ) as AllProducts,
@Aggregation.referenceElement: ['Product']
@Aggregation.Default: #COUNT_DISTINCT
cast( 15 as abap.int4 ) as DistinctProducts,
_SalesOrder,
_Product
}
上面代码演示了一个完整的聚合视图和注解的使用方式.
下面这个是比较新的功能, 计算个数的. 它会对 referenceElement 指定的字段进行个数统计.
@Aggregation.referenceElement: ['Product']
@Aggregation.Default: #COUNT_DISTINCT
cast( 15 as abap.int4 ) as DistinctProducts,
OData Interpretation of Aggregation Annotations
拥有 aggregation annotations 的数据模型和没有 aggregation annotations 的数据模型在 OData 里具有不同的行为.
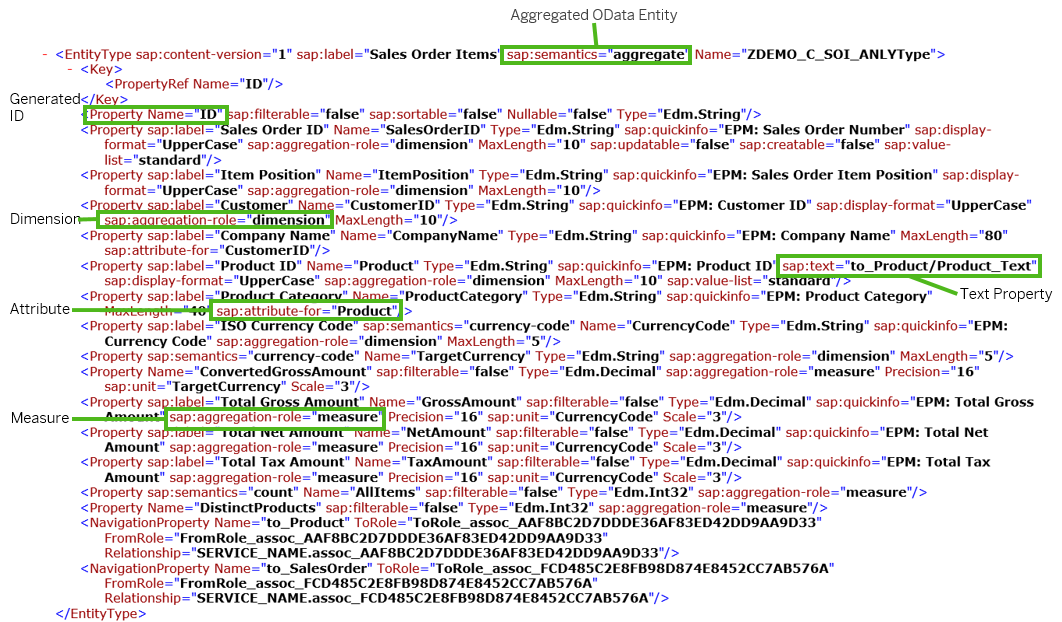
-
Aggregated OData Entities: 拥有 aggregation annotations
@Aggregation.Default: #<AGGR_FUNCTION>的数据模型在 OData 的 Metadata 里的 Entity Type 上会有属性sap:semantics="aggregate", 说明此实体是可以被聚合的也就是有维度和度量字段. -
Measures: 被注解为聚合的字段会在 OData annotations 里生成属性
sap:aggregation-role="measure"可以告知前端这些字段在后台是可以聚合的. -
Dimensions: 除了被指定 measures 和 attributes 的其他字段都会被当作 dimensions , 会被标记
sap:aggregation-role="dimension", OData 会根据这些 dimensions 对数据进行分组聚合. 每个 dimension 可以最多拥有一个 text 属性对应的文本字段, 是通过sap:text="<TEXT_PROPERTY>"标记的. -
Attributes: Dimensions can have attributes. Attributes are elements that are annotated with the annotation
@Consumption.groupWithElement: 'ElementRef'. The attributes are always considered as an addition to their corresponding dimension. Attributes are annotated by OData withsap:attribute-for="<DIMENSION>". 根据标记为 attributes 的字段查询 measures 时, OData 会根据 attribute 对应的 dimension 对 measures 进行聚合. -
Generated ID for Aggregated OData Entities: 如果没有聚合的话, 数据记录可以通过数据库主键确定唯一的某一行. 但对于聚合记录来说主键就无法确定此行聚合后的数据了. 所以针对每一行聚合后的数据会添加一个 ID 主键字段
<Property Name="ID"/>来确定此行记录, 便于单独读取它.
This behavior is exemplified by a request on the entity that supplies the metadata above. It retrieves sales order items. The following request selects the generated ID ( ID), the dimension Product, and some aggregated measures related to the selected dimension.
.../sap/opu/odata/SAP/<service_name>/ZDEMO_C_SOI_ANLY?$select=ID,Product,GrossAmount,NetAmount,TaxAmount,AllProducts
This request retrieves the following result:

Requesting Data from an Aggregated Entity
Results of requesting data from aggregated entities depend on the elements you select in your OData request. Grouping and aggregation are both driven by the elements you request with the parameter $select in entity set queries. The result of a query consists of aggregated entities with distinct values for the requested dimension properties and requested measures are aggregated using the aggregate function with which the measure elements are annotated in CDS.
If an attribute is requested, the result is grouped by its corresponding dimension and within that group it is grouped by the attribute itself.
If you use a SAP Fiori app, the
$selectstatement of the OData request directly depends on the columns you select in the list reporting app. The following descriptions of requesting data with OData can also be managed by selecting the respective columns in your Fiori App.
If not all key elements are included in the OData request, the requested dimensions are grouped and the requested measures are aggregated according to their annotated aggregate function. For every distinct combination of dimension values (after evaluating $filter), the result includes an aggregated entity with aggregated values for the requested measures.
Each group record is given its own generated ID, which can be reused in requests to retrieve the same results.
Only if no dimension and no attribute are requested does the result show the aggregate data of measures for the whole entity set.
You can still execute other query options, such as $filter or $orderby on grouped requests. The filtering is executed before the grouping, so that the groups are created from the available records after the filtering. The ordering is executed after the grouping, which means the records within a group are ordered according to the query option.
You can filter for properties that you do not select, but you cannot order by properties that are not included in the
$selectdue to the order of executing query options mentioned above. (因为 HANA 是一个支持列存储的数据库, 会在查询视图或者表时只读取需要查询的列(指在$select列出的), 如果没有在$select或者 SQL 的 select 列出的就不会被读取, 所以也就不能被排序; 另外一方面如果强制读取 orderby 的列, 又因为 orderby 是在 grouping 之后的, 所以不能确定按哪种方式 grouping, 所以也就不能强制读取 orderby 的列)
Navigating and Expanding from a Group Record
You can navigate directly from a group record to one of the properties that are included in the group, for example properties that you have selected previously.
Assume you have an aggregated entity of sales order items and you group them by product. From this group record, you can navigate directly to the associated entity of products if the association exists in CDS.
The same holds true for the query option $expand. Only properties that are selected can be expanded.
The target entity of the navigation or the expand is also given an aggregated ID if the underlying data model is also aggregated.
Parameters and Aggregated Entities
If your CDS view contains visible parameters (not annotated with @Consumption.hidden: true), the OData entity is generated with the same properties for each parameter as in non-aggregated entities. However, the naming pattern differs.
Analytical Scenarios With Parameters
CDS also covers analytical scenarios, where measures and dimensions can be defined. The runtime of these CDS views is provided by the Analytical Engine or by SADL, depending on the complexity of the view.
A CDS view is considered to be an analytical view if it contains at least one occurrence of the
@DefaultAggregationannotation.
define view SalesOrdersWithConvAmounts
with parameters
currency : snwd_curr_code
as select from snwd_so as SalesOrder
{
...
@DefaultAggregation: #SUM
price
...
}
In the case of views with visible parameters, the mapping of CDS artifacts to the OData metamodel is different, since the parameter values do not need to be supplied before executing an OData query. As a consequence, a CDS view with parameters and analytical annotations has to be mapped to two OData entity sets - parameter and result entity set. Let’s suppose the name of the CDS view is ‘CDSView’. The OData artifact names would be as follows:
| OData | Name |
|---|---|
| Result Entity Name | CDSViewResult |
| Result Entity Set Name | CDSViewResults |
| Parameter Entity Name | CDSViewParameters |
| Parameter Entity Set Name | CDSView |
| OData Association | |
| OData Association Set | |
| Navigation Property | Result |
Comments